Welcome to the homepage for  The Library, a Discord-based chatroom for fiction writers. Discord is a free chat application for the web, desktop, and mobile devices. Find out more about us!
The Library, a Discord-based chatroom for fiction writers. Discord is a free chat application for the web, desktop, and mobile devices. Find out more about us!
Using RegEx in Google Docs
We all know about Ctrl+F for Find, and most of us know about Ctrl+H for find and replace (shown below). The “Match case” box is handy for finding things that exactly match the upper-case or lower-case letters you type. But what’s that box labeled “Match using regular expressions” for?
Regular Expressions, or RegEx for short, are tools for searching through text. They allow us to perform more complex searches.
We’ll work through several examples, from simple to complex, to show how useful RegEx can be.
Example 1
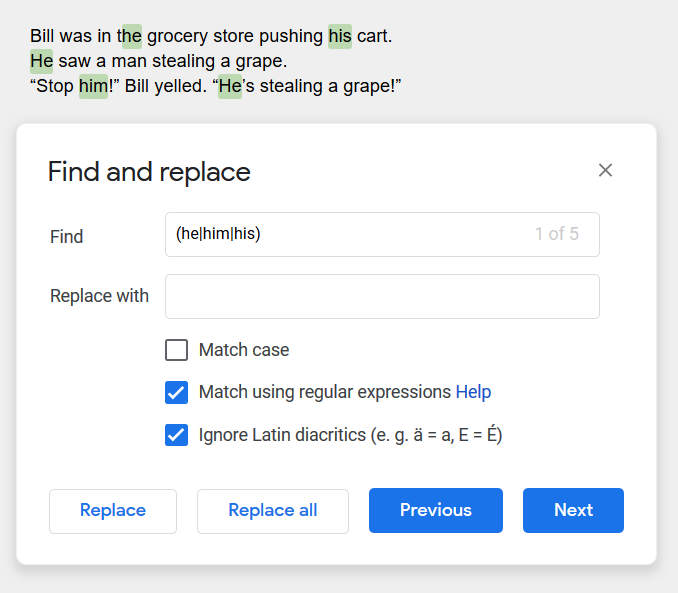
For example, let’s say you want to search for more than one word at once. You’d have to run a bunch of searches. But instead, you can do one using a Regular Expression: (word1|word2|word3) and so on. For example:
Example 2
Note that in the example above, the search accidentally picks up the “he” in the word “the”. How do we search for “whole words only”?
One of the most useful RegEx tokens to know is \b which means a word boundary. This allows you to search for “whole words only”. Let’s take Example 1 above. If you change it to \b(he|him|his)\b you won’t accidentally pick up the “he” part of the word “the” (and if you wanted to find only matches within other words, you’d use two \B instead!)
Let’s use \b in conjunction with [A-Z] to find words that are written in ALL CAPS. We can do this with the RegEx string \b[A-Z]{2,}\b
- \b indicates a word boundry (the spaces around a word)
- [A-Z] says to look for these alphabet letters
- {2,} says to look for the letters A-Z used 2 or more times (if it was {1,} it would pick up the word “I”). (You could also use {2,8} to search for words that are at least 2 but no more than 8 letters long, for example.)
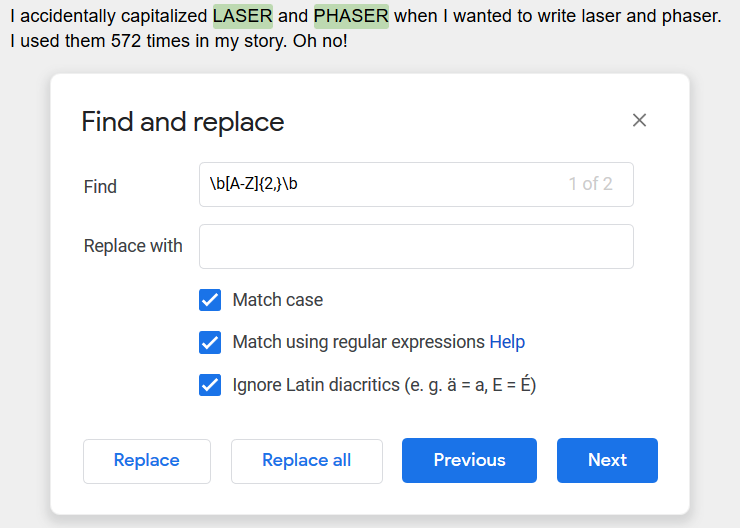
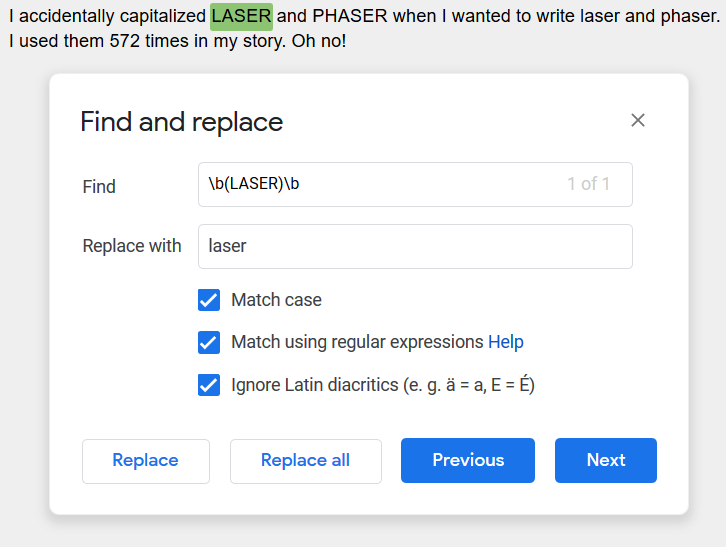
The example above will find ALL the all-caps words, not just LASER. If you want to replace specific words (lets say you inconsistently used LASER and laser), you’d do it like this: \b(LASER)\b
Example 3
Let’s say you have a bad habit of occasionally using the antiquated “said Bill” instead of the more modern “Bill said” and you want to go through your text and find them all.
You can search for that with said [A-Z] which says to look for the word said, followed by any the letters A-Z. Note that if you turn on “Match case” it will only search for capital letters.
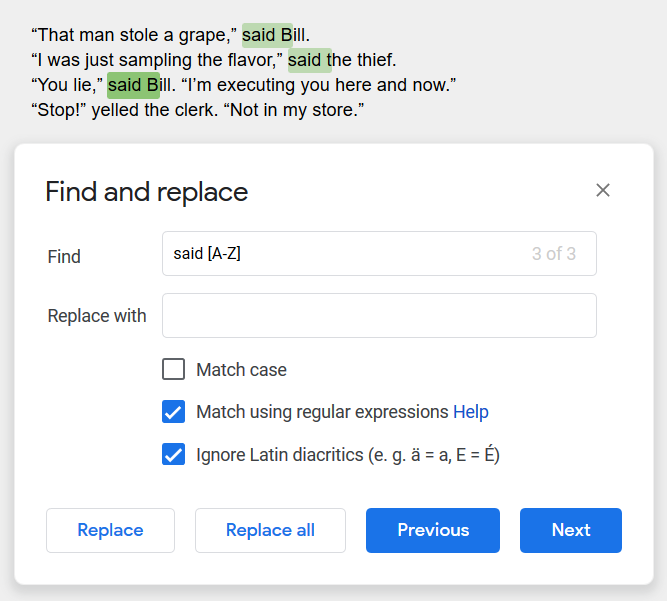
Well, that caught three of the four problems. Let’s try to modify that search to make it more universal. We can add some other dialogue verbs to the list: (said|yelled|muttered) [A-Z]
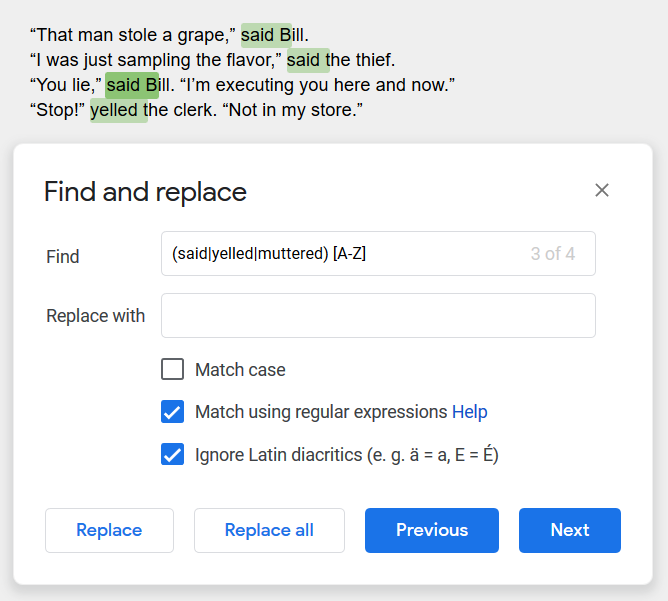
Now we’ve found them all.
Example 4
Let’s say you are a bit inconsistent in how you use okay (sometimes writing OK, ok, O.K., o.k., or okay), and you want to replace them all with just “okay”. Well, you don’t want to replace the “ok” in the middle of the word “broken”, or any other words.
So, we construct a RegEx pattern like so: \b(ok)\b to find whole words only
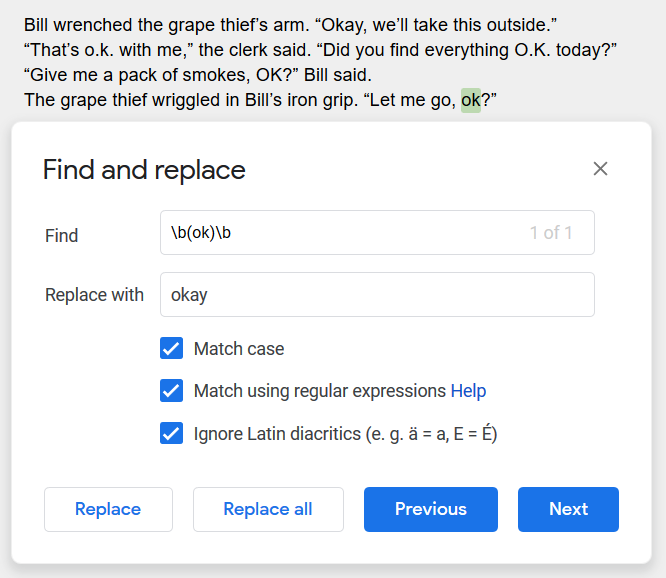
(You don’t technically need the parentheses here, but it’s easier to read with them.)
Well, that found one of the “ok” uses, and it didn’t find the “ok” in the middle of “smokes”, so that’s good. But how do we find the others?
Unfortunately, \b(ok|o.k.)\b doesn’t work, because the period (.) is a special character in RegEx. We can “escape” the period and search for it literally with a backslash, like so: \b(ok|o\.k\.)\b but this doesn’t work either because \b is a word boundary, and word boundaries include periods.
Instead we can use \W(ok|o\.k\.)\W because the token \W searches for any non-word character:
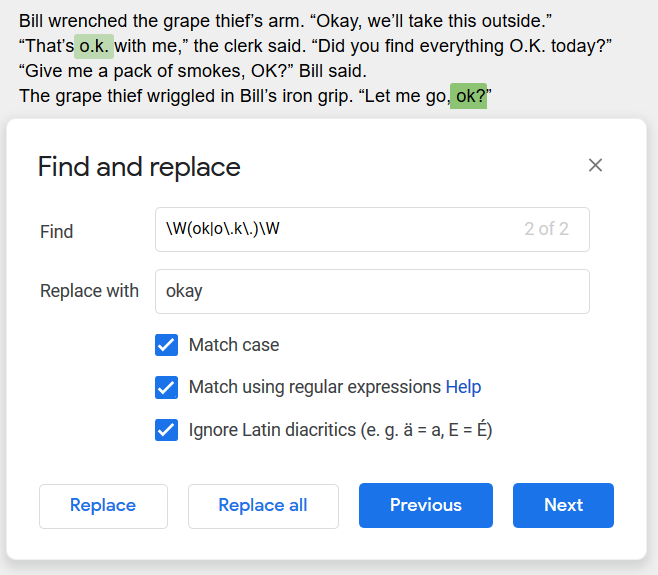
Example 5
The above highlights both versions of OK, and it works if you’re trying to find something. But it isn’t ideal if you also want to use “Replace”, because it includes these excess characters, which will vary and can’t be easily be replaced.
To fix this, we need to use lookbehinds and lookaheads.
- A lookbehind looks for things before (behind) some text. It looks like this: (?<=[stufftosearch]|^)
- A lookahead looks for things after (ahead of) some text. It looks like this: (?=[stufftosearch]|$)
Note that the ^ means to also look at the start of a line, and the $ means to also look at the end of a line. Typically this is actually the start or end of the entire document. You don’t technically need these, but it’s a good idea when using lookbehinds/lookaheads.
Since we are searching for non-word characters with \W, let’s try that. We put the (ok|o.k.) in between, like so: (?<=\W|^)(ok|o.k.)(?=\W|$)
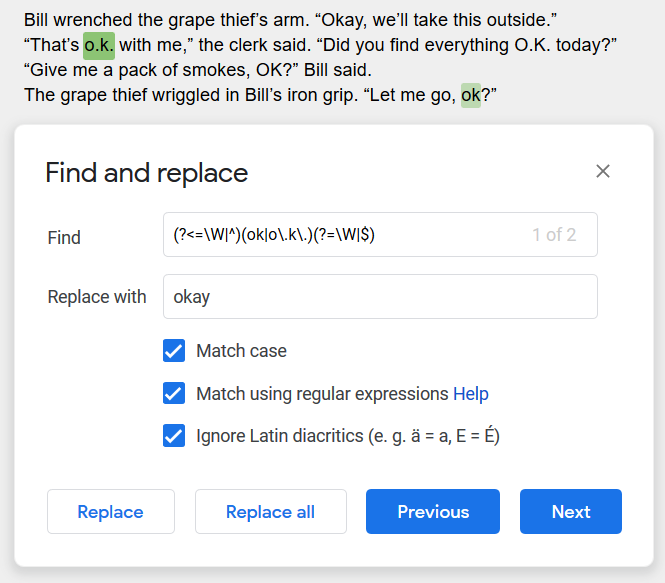
That works! If we replace that (ok|o\.k\.) with the capitalized version (OK|O\.K\.) we can find those too.
Example 6
Now that you know what lookaheads and lookbehinds are, here’s another very handy use of them: replacing simple quotation marks with pretty quotation marks.
- Simple quotes are
"and' - Pretty quotes are
“ ”and‘ ’
So, we can use these RegEx searches (\w is a “word character”, meaning those characters you would use in a word):
\"(?=\w)searches for simple double quotes at the beginning of a word, so you can replace them with “- Explanation: Searches for a double quotation mark, followed by a word character (\w)
(?<=\S)\"searches for simple double quotes at the end of a word, so you can replace them with ”- Explanation: Searches for a non-whitespace character (\S), which will include question marks, em dashes etc, followed by a double-quotation mark
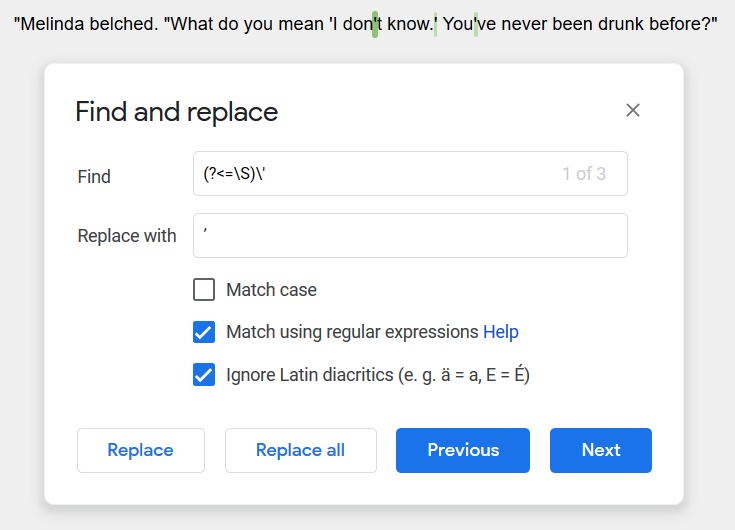
\B\'(?=\w)searches for simple single quotes at the beginning of a word, so you can replace them with ‘- Explanation: Searches for a non-word boundary (\B), followed by a single quote, followed by a word-character. We need to \B to avoid accidentally picking up apostrophes in contractions, like can’t.
(?<=\S)\'searches for simple single quotes in the middle or at the end of a word, so you can replace them with ’- Explanation: Searches for a non-whitespace character (\S), which will include question marks, em dashes etc, followed by a double-quotation mark
Here’s a screenshot of the last one:
You can also replace pretty quotes with simple quotes, but it’s much easier RegEx since simple quotes are not directional.
- Search for (“|”) and replace with
" - Search for (‘|’) and replace with
'
Example 7
Let’s get back to Example 5 and the issues with O.K. How do you detect “O.K.” at the beginning of a sentence, versus “O.K.” used in the middle of the sentence?
Let’s use this passage:
“OK,” Bill said. “I’ll take him outside and kill him over a grape.”
“Great,” the clerk said, “make sure to clean up after, OK?”
Bill pulled a gun. OK, it was a water pistol.
“Wait,” the thief said, “I want to live.”
Bill put away the gun. “OK, then pay the man for that grape you ate.”
“OK, OK,” the thief said. “I’m sorry, OK. Where are you from?”
“Oklahoma,” Bill said, “OK?”
Some of these OKs needs to be replaced with “Okay” and the others with “okay”. How do we know?
You can use lookbehinds and lookaheads to figure it out.
The final solution for the capitalized ones is as follows:
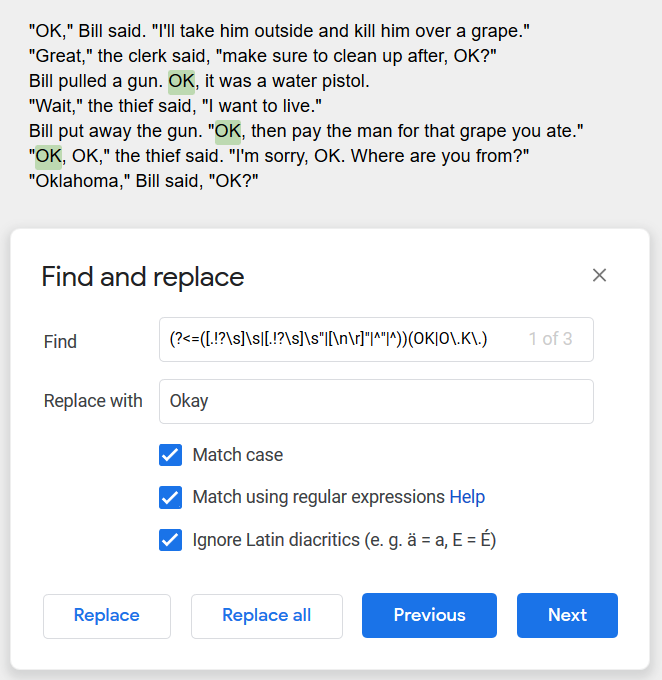
(?<=([.!?\s]\s|[.!?\s]\s”|[\n\r]”|^”|^))(ok|o.k.)(?=(\W|$))
Let’s break that up:
- (?<=( beginning of lookbehind
- [.!?\s]\s searches for any [ending punctuation, space characters (\s)] followed by a space (second \s). This will match cases at the beginning of a sentence, like:
Bill pulled a gun. OK, it was a water pistol. - |acts as an “or” operator
- [.!?\s]\s” searches for the same thing, in dialogue format.
Bill put away the gun. “OK, then pay the man for that grape you ate.” - |acts as an “or” operator
- [\n\r]” searches for a new line (\n) or carriage return (\r) followed by a quotation mark, for dialogue lines that start with OK, like:
“OK, OK,” the thief said. “I’m sorry, OK.” - |acts as an “or” operator
- ^” searches at the very beginning of the entire document, like:
“OK,” Bill said. “I’ll take him outside and kill him over a grape.”- Unfortunately, Google Docs doesn’t support this properly (for shame) but it is correct RegEx.
- |acts as an “or” operator
- ^ searches at the very beginning of the entire document, but without a quote after it, in case you literally started the file with something like:
OK, this is the story of the stolen grape.- Unfortunately, Google Docs doesn’t support this properly (for shame) but it is correct RegEx.
- )) closes the lookbehind
- (OK|O.K.) is what we’re searching for (either OK or O.K.)
- (?=(\W|$)) is the lookahead, which is what we want after the OK – a whitespace character (\W) so we don’t accidentally pick up things like
“Oklahoma is where I’m from.” and accidentally turn it into
“Okaylahoma is where I’m from.”
Note that if you’re using pretty quotes ( “ instead of " ) you may need to search for those instead.
Here it is in text (unfortunately due to the limitations of Google Docs, the first one isn’t caught, but how many documents start with “OK” as their first word?):
Example 8
And then here is the much-simpler lower-case version of Example 7:
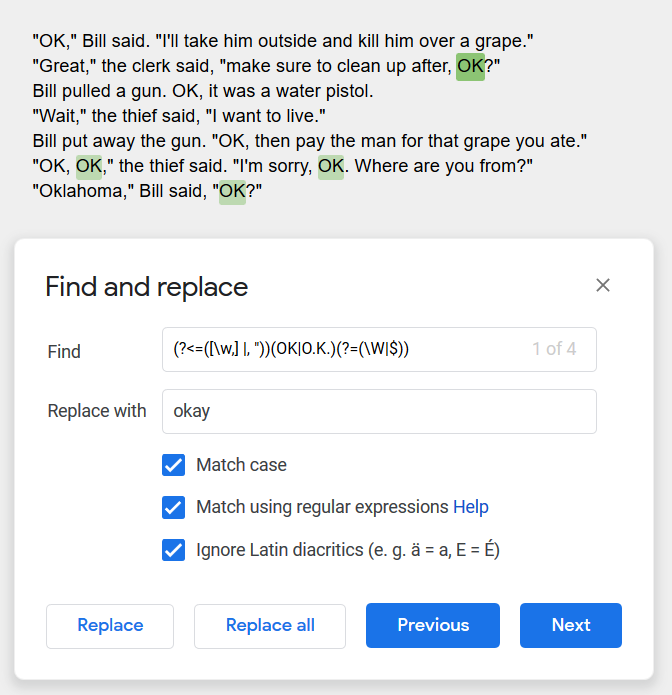
(?<=([\w,] |, “))(OK|O.K.)(?=(\W|$))
- (?<=( beginning of lookbehind
- [\w,] searches for either a word character (\w) or a comma, followed by a space (literal space this time, not \s). This will match cases in the middle of a sentence, like:
I’m sorry, OK. - |acts as an “or” operator
- , “ searches for the same thing, in dialogue format, a comma followed by a space followed by a quotation mark.
Bill put away the gun. “OK, then pay the man for that grape you ate.” - )) closes the lookbehind
- (OK|O.K.) is what we’re searching for (either OK or O.K.)
- (?=(\W|$)) is the lookahead, which is what we want after the OK – a whitespace character (\W) so we don’t accidentally pick up things like
“I’m from Oklahoma.” and accidentally turn it into
“I’m from Okaylahoma.”
Note that if you’re using pretty quotes ( “ instead of ” ) you may need to search for those instead.
Here it is in text:
If you used say, a ton of variants of okay, you could replace the middle with something like: (ok|OK|o\.k\.|O\.K\.) to catch them all.
Closing thoughts
When you’re building your RegEx patterns, I strongly recommend using RegEx101.com which is a great tool. Just make sure to set the “flavor” on the left to ECMA Script (Javascript), which is what Google Docs uses. There is a great glossary of all the RegEx special characters and terms in the lower right panel as well.
Also note that certain types of operations, such as Negative Lookbehinds, are not supported by all browsers. Chrome has the best support for the latest RegEx tools.
Good luck, and I hope you now understand a bit more about RegEx and also why you should just use “okay” instead of the abbreviations!